Go 的 sync.Map 学习
map 的并发问题
实际上 Go 的 map 类型是有并发问题的,一个 goroutine 一直读,一个 goroutine 一只写同一个键值,即使读写的键不相同,而且 map 也没有 "扩容" 等操作,代码还是会报错。
func main() {
m := make(map[int]int)
go func() {
for {
_ = m[1]
}
}()
go func() {
for {
m[2] = 2
}
}()
select {}
}
抛出错误:

Go 1.9 之前的解决方案,它使用嵌入 struct 为 map 增加一个读写锁。
var counter = struct{
sync.RWMutex
m map[string]int
}{m: make(map[string]int)}
读数据的时候很方便的加锁:
counter.RLock()
n := counter.m["some_key"]
counter.RUnlock()
fmt.Println("some_key:", n)
写数据的时候:
counter.Lock()
counter.m["some_key"]++
counter.Unlock()
性能测试
这里写一个基准测试用于测试以下的并发方案性能
- sync.RWMutex 锁 + Map
- sync.Mutex 锁 + Map
- sync.Map
完整的代码参考 Gist 代码片段
$ go test -v -run=none -bench=. -count=10 -cpu=2,4,8,16,32,64,128,256,512 | tee bench.txt
$ benchstat bench.txt
输出(细节就不展示了):
goos: linux
goarch: amd64
pkg: stgo
cpu: Intel(R) Core(TM) i5-10500 CPU @ 3.10GHz
BenchmarkLoadStoreCollision
BenchmarkLoadStoreCollision/*main.MutexMap
BenchmarkLoadStoreCollision/*main.MutexMap-12 17161202 68.84 ns/op
BenchmarkLoadStoreCollision/*main.RWMutexMap
BenchmarkLoadStoreCollision/*main.RWMutexMap-12 14614050 78.86 ns/op
BenchmarkLoadStoreCollision/*sync.Map
BenchmarkLoadStoreCollision/*sync.Map-12 298888142 4.091 ns/op
PASS
可以看到,使用 sync.Map 的性能远远高于上面两种并发 Map 方案
sync.Map 的数据结构
实际上这个 sync.Map 内部是由两个 Map 构成的,分别是 read 和 dirty 这两个 Map
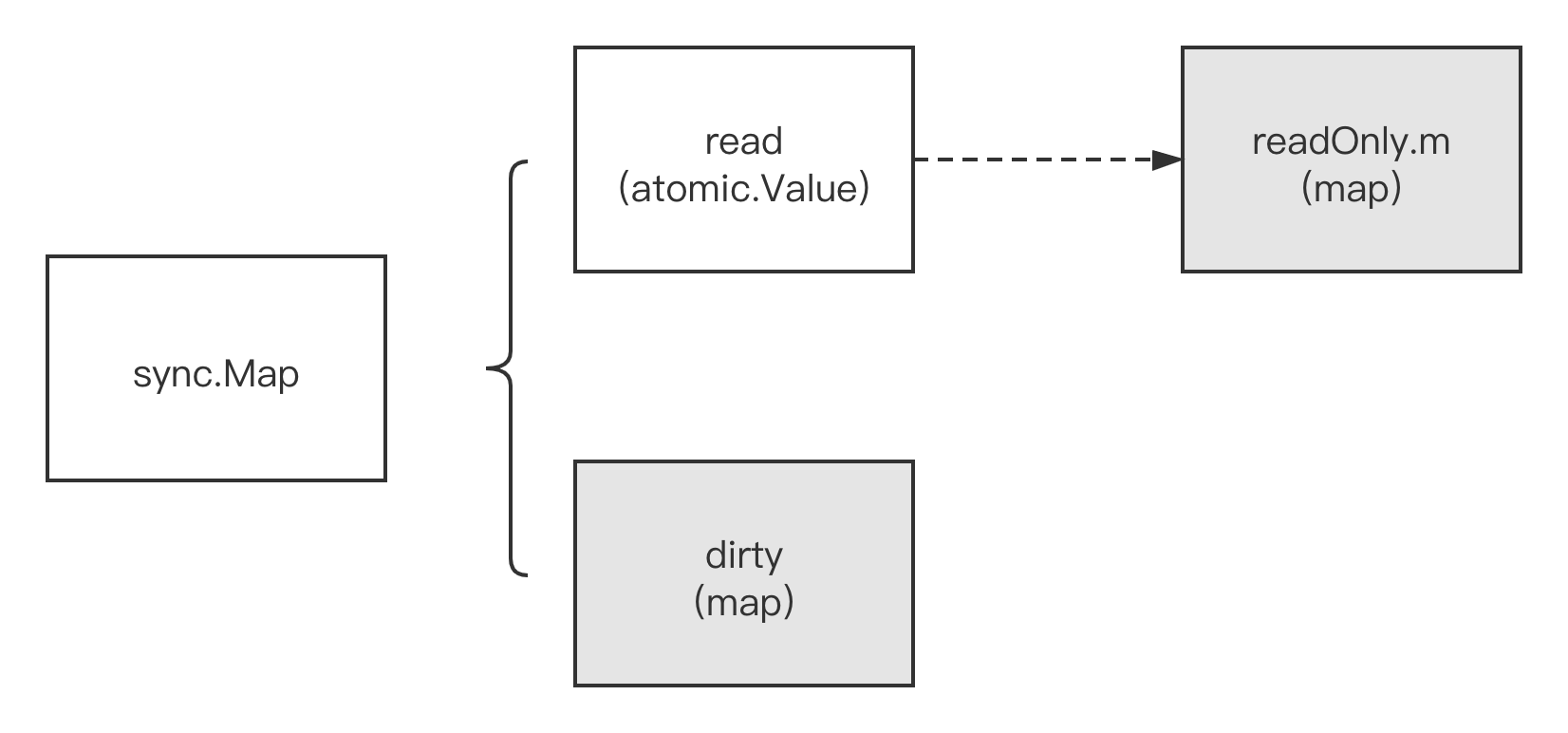
read(这个 map)好比整个 sync.Map 的一个 “高速缓存”,当 goroutine 从 sync.Map 中读取数据时,sync.Map 会首先查看 read 这个缓存层是否有用户需要的数据(key 是否命中),如果有命中,则通过原子操作将数据读取并返回。
type Map struct {
// 当涉及到 dirty 数据的操作的时候,需要使用这个锁
mu Mutex
// read 包含 map 内容的一部分,这些内容对于并发访问是安全的(有或不使用 mu)。
//
// read 字段 load 总是安全的,但是必须使用 mu 进行 store。
//
// 存储在 read 中的 entry 可以在没有 mu 的情况下并发更新,
// 但是更新已经删除的 entry 需要将 entry 复制到 dirty map 中,并使用 mu 进行删除。
read atomic.Value // readOnly
// dirty 含了需要 mu 的 map 内容的一部分。为了确保将 dirty map 快速地转为 read map,
// 它还包括了 read map 中所有未删除的 entry。
//
// 删除的 entry 不会存储在 dirty map 中。在 clean map 中,被删除的 entry 必须被删除并添加到 dirty 中,
// 然后才能将新的值存储为它
//
// 如果 dirty map 为 nil,则下一次的写行为会通过 clean map 的浅拷贝进行初始化
dirty map[interface{}]*entry
// 当从 Map 中读取 entry 的时候,如果 read 中不包含这个 entry,会尝试从 dirty 中读取,
// 这个时候会将 misses 加一。
//
// 当 misses 累积到 dirty 的长度的时候,dirty map 将被提升为 read map(处于未修改状态)
// 并且 map 的下一次 store 将生成新的 dirty 副本。
misses int
}
从 misses 的描述中可以大致看出 sync.Map 的思路是发生足够多的读时,就将 dirty map 复制一份到 read map 上。 从而实现在 read map 上的读操作不再需要昂贵的 Mutex 操作。
这个 read 的结构比较特殊,是一个 atomic.Value 类型。实际上它对应的是 readOnly 类型
type readOnly struct {
m map[interface{}]*entry
amended bool // 如果 Map.dirty 里有些数据不在 read.m 的时候,这个值为true
}
这个 amended 表示 Map.dirty 中有 readOnly.m 未包含的数据,所以如果从 Map.read 找不到数据的话,还要进一步到 Map.dirty 中查找。
实际这个 entry 类型存储的是一个指针,它包含一个指针 p,指向用户存储的 value 值。
type entry struct {
p unsafe.Pointer // *interface{}
}
虽然 read 和 dirty 有冗余数据,但这些数据是通过指针指向同一个数据,所以尽管 Map 的 value 会很大,但是冗余的空间占用还是有限的。
p 有三种值:
- nil: entry 已被删除了,并且 m.dirty 为 nil
- expunged: entry 已被删除了,并且 m.dirty 不为 nil,而且这个 entry 不存在于 m.dirty 中
- 其它: entry 是一个正常的值
以上是 sync.Map 的数据结构
Load 读取数据
func (m *Map) Load(key interface{}) (value interface{}, ok bool) {
read, _ := m.read.Load().(readOnly)
// 从 readOnly 这个 Map 中取得值
e, ok := read.m[key]
// 如果不存在,且 dirty 里面存在 read 里面不存在的 entry 时
if !ok && read.amended {
m.mu.Lock()
read, _ = m.read.Load().(readOnly)
e, ok = read.m[key]
// 双检查,避免加锁的时候 m.dirty 提升为 m.read 这个时候 m.read 可能被替换了。
if !ok && read.amended {
e, ok = m.dirty[key]
// 不管m.dirty中存不存在,都将misses计数加一
// missLocked() 中满足条件后就会提升 m.dirty
m.missLocked()
}
m.mu.Unlock()
}
if !ok {
return nil, false
}
return e.load()
}
上面每一步基本都有解释了,其中主要是双检查的处理,因为第一次 !ok && read.amended 的时候并不是一个原子操作,在加锁之前,m.dirty 可能被提升为 m.read,所以加锁后还得再检查 m.read
值得注意的是这个 missLocked 是如何提升 dirty 的
func (m *Map) missLocked() {
m.misses++
if m.misses < len(m.dirty) {
return
}
m.read.Store(readOnly{m: m.dirty})
m.dirty = nil
m.misses = 0
}
可以看到当 dirty 被提升后,直接将 dirty 置空,值得注意的是这个 Store 函数是会直接把整个 dirty 拓扑到 read 里面,所以 dirty 要保存完整的 Map 数据(因为提升 dirty 字段为 read 的时候非常快,不用一个一个的复制,而是直接将这个数据结构作为 read 字段的一部分),因此,无论是存储还是读取,read map 中的值一定能在 dirty map 中找到。
Store 写数据
首先遇到的第一种情况就是更新一个已经存在的值
func (m *Map) Store(key, value interface{}) {
read, _ := m.read.Load().(readOnly)
// 修改一个已经存在的值
// 读取 read map 中的值
// 如果读到了,则尝试更新 read map 的值,如果更新成功,则直接返回,
// 如果这个值是已经被删除的或者没有读到的,那么还需继续处理
if e, ok := read.m[key]; ok && e.tryStore(&value) {
return
}
(...)
}
其中这个 tryStore 是通过 CAS 乐观锁来更新数据的
// expunged 是一个任意的指针,用于标记被删除的数据
var expunged = unsafe.Pointer(new(interface{}))
// 尝试更新值
func (e *entry) tryStore(i *interface{}) bool {
for {
p := atomic.LoadPointer(&e.p)
if p == expunged {
return false
}
if atomic.CompareAndSwapPointer(&e.p, p, unsafe.Pointer(i)) {
return true
}
}
}
继续看 Store() 剩下的部分。下面的情况就相对复杂一些了,在锁住结构后, 要做的第一件事情就是更新刚才读过的 read map。原因同 Load() 方法,都是因为 m.dirty 可能被提升为 m.read,所以加锁后还得再检查 m.read
m.mu.Lock()
read, _ = m.read.Load().(readOnly)
// 如果是存在于 read 里面
if e, ok := read.m[key]; ok {
// 首先将该 Key 标记成未被删除
if e.unexpungeLocked() {
// m.dirty 中不存在这个键,所以加入 m.dirty
m.dirty[key] = e
}
// 更新
e.storeLocked(&value)
// 如果存在于 dirty 里面则直接更新
} else if e, ok := m.dirty[key]; ok {
e.storeLocked(&value)
} else {
// 如果 m.dirty 中没有新的数据,往 m.dirty 中增加第一个新键
if !read.amended {
// 从 m.read 中复制未删除的数据
m.dirtyLocked()
// 然后告诉 readOnly,dirty 里面存在它不存在的内容
m.read.Store(readOnly{m: read.m, amended: true})
}
// 将这个 entry 加入到 m.dirty 中
m.dirty[key] = newEntry(value)
}
m.mu.Unlock()
其中这个 dirtyLocked 用于初始化 dirty,它会把 read 中未被删除的 entry 复制过去
func (m *Map) dirtyLocked() {
if m.dirty != nil {
return
}
read, _ := m.read.Load().(readOnly)
m.dirty = make(map[interface{}]*entry, len(read.m))
for k, e := range read.m {
if !e.tryExpungeLocked() {
m.dirty[k] = e
}
}
}
func (e *entry) tryExpungeLocked() (isExpunged bool) {
p := atomic.LoadPointer(&e.p)
for p == nil {
if atomic.CompareAndSwapPointer(&e.p, nil, expunged) {
return true
}
p = atomic.LoadPointer(&e.p)
}
return p == expunged
}
Delete 删除数据
从实现上来看,删除操作相对简单,当需要删除一个值时,移除 read map 中的值,本质上仅仅只是解除对变量的引用。 实际的回收是由 GC 进行处理。 如果 read map 中并未找到要删除的值,才会去尝试删除 dirty map 中的值。
// Delete 删除 key 对应的 value
func (m *Map) Delete(key interface{}) {
// 获得 read map
read, _ := m.read.Load().(readOnly)
// 从 read map 中读取需要删除的 key
e, ok := read.m[key]
// 如果 read map 中没找到,且 read map 与 dirty map 不一致
// 说明要删除的值在 dirty map 中
if !ok && read.amended {
// 在 dirty map 中需要加锁
m.mu.Lock()
// 再次读 read map
read, _ = m.read.Load().(readOnly)
// 从 read map 中取值
e, ok = read.m[key]
// 没取到,read map 和 dirty map 不一致
if !ok && read.amended {
// 删除 dierty map 的值
delete(m.dirty, key)
}
m.mu.Unlock()
}
// 如果 read map 中找到了
if ok {
// 则执行删除
e.delete()
}
}
func (e *entry) delete() (hadValue bool) {
for {
// 读取 entry 的值
p := atomic.LoadPointer(&e.p)
// 如果 p 等于 nil,或者 p 已经标记删除
if p == nil || p == expunged {
// 则不需要删除
return false
}
// 否则,将 p 的值与 nil 进行原子换
if atomic.CompareAndSwapPointer(&e.p, p, nil) {
// 删除成功(本质只是解除引用,实际上是留给 GC 清理)
return true
}
}
}
整体复盘
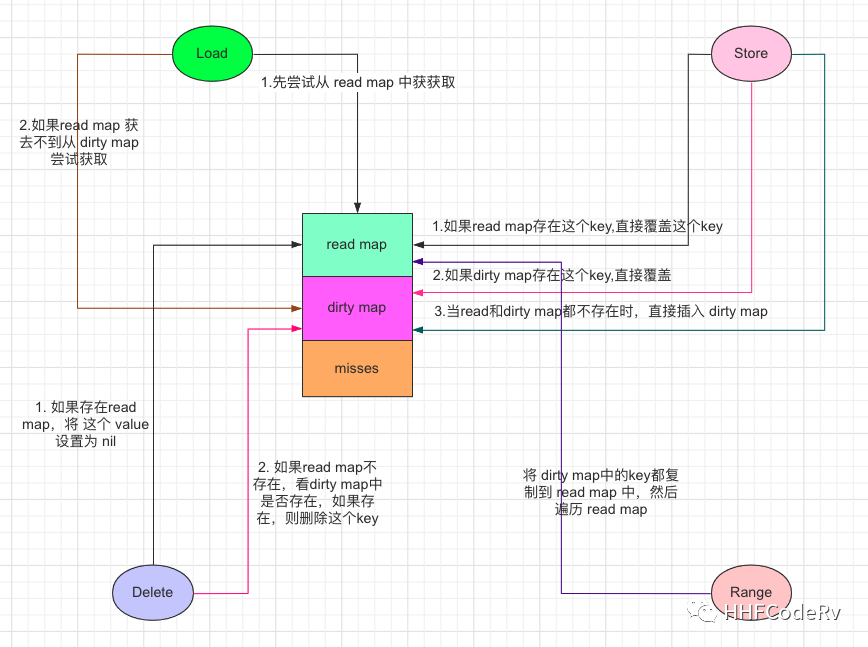
TODO: 待更新....